I don’t mean to suggest that Git is a CRM tool, but rather that Git has features that you can employ to manage code for multiple clients in ways that make them happier and you more efficient.
At various times in my career, I’ve worked on code that was mostly shared across projects for several different audiences. As an independent consultant, I had utility code that I employed solving problems for various clients. As a developer at a maker of OEM systems, I lightly customized common feature code for numerous customers. And when building plugins for large systems, a lot of glue and foundation code can be shared between different implementations.
The legal agreements around such work often require that the client have access to the source but, in my experience, that access is rarely exclusive. If you can make common code common and still share all the code used by a client with that client, you are more efficient because you don’t have to reinvent the wheel every time and they receive more robust solutions that build on code shared with other implementations. It’s not quite the “many eyes make all bugs shallow” ideal of open source, but it has some of the same advantages. The key to this reuse is disciplined branch management. In the rest of this post, I’ll show you how.
Consider a project being done for Acme Widgets, developed with an eye toward portability and modularity. Details of software modules and implementation language really don’t matter, so I’ll simplify the discussion by illustrating with changes in a single text file.
Document Title
This document describes some software.
It has features.
It is customizable.
We get started by creating a repo for shared source and putting this text in a file, doc.txt.
$ mkdir shared
$ cd shared/
$ git init
Initialized empty Git repository in C:/Code/blog/shared/.git/
$ touch .gitignore
$ git add .gitignore
$ git commit -m "Shared: Initial commit"
[master (root-commit) 33dd3c5] Shared: Initial commit
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 .gitignore
$ emacs doc.txt
$ git add doc.txt
$ git commit -m "Shared: First version of document"
[master 85d0374] Shared: First version of document
1 file changed, 7 insertions(+)
create mode 100644 doc.txt
Let’s add some common features:
Document Title
This document describes some software.
It has features.
* Feature 1
* Faeture 2
It is customizable.
This common “code” is still on the master branch
$ git diff
diff --git a/doc.txt b/doc.txt
index f1cfe19..2c3bf02 100644
--- a/doc.txt
+++ b/doc.txt
@@ -4,4 +4,7 @@ This document describes some software.
It has features.
+* Feature 1
+* Faeture 2
+
It is customizable.
$ git add doc.txt
$ git commit -m "Shared: Add features 1 and 2"
[master 975c1d3] Shared: Add features 1 and 2
1 file changed, 3 insertions(+)
Now that there is a base to build on, let’s start working on client-specific work. First, we create a repository for the client’s view of the project.
$ cd ..
$ mkdir acme
$ cd acme
$ git init
Initialized empty Git repository in C:/Code/blog/acme/.git/
Then, we make that client repository a remote for our shared repository.
$ cd ../shared
$ git remote add Acme file:///c/code/blog/acme
$ git remote
Acme
And make a client-specific branch in the shared repository.
$ git checkout -b acme
Switched to a new branch 'acme'
And add client notes to the document.
Document Title
This document describes some software.
It has features.
* Feature 1
* Faeture 2
It is customizable.
Acme-specific features include:
* Feature A
* Feature B
And check them in on the client-specific branch.
$ git diff
diff --git a/doc.txt b/doc.txt
index 1dda3c5..737c272 100644
--- a/doc.txt
+++ b/doc.txt
@@ -8,3 +8,8 @@ It has features.
* Faeture 2
It is customizable.
+
+Acme-specific features include:
+
+* Feature A
+* Feature B
$ git add doc.txt
$ git commit -m "Acme: Add features A and B"
[acme 89547d7] Acme: Add features A and B
1 file changed, 5 insertions(+)
In discussion with Acme, you find that their Feature C really has general utility, so you choose to add it as Feature 3 to the common code. To do this we work on the master branch then merge that common change onto the client branch.
[master 53f5a0c] Shared: Add feature 3
$ git checkout master
Switched to branch 'master'
$ emacs doc.txt
$ git diff
diff --git a/doc.txt b/doc.txt
index 2c3bf02..5daa37c 100644
--- a/doc.txt
+++ b/doc.txt
@@ -6,5 +6,6 @@ It has features.
* Feature 1
* Faeture 2
+* Feature 3
It is customizable.
$ git add doc.txt
$ git commit -m "Shared: Add feature 3"
[master 53f5a0c] Shared: Add feature 3
1 file changed, 1 insertion(+)
$ git checkout acme
Switched to branch 'acme'
$ git merge master
Auto-merging doc.txt
Merge made by the 'recursive' strategy.
doc.txt | 1 +
1 file changed, 1 insertion(+)
All this work is local and has a global view of common and client-specific features. When it is time to share the development with the client, you push just the client-specific branch to the client-specific repository.
$ git push Acme acme:upstream
Counting objects: 18, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (16/16), done.
Writing objects: 100% (18/18), 1.60 KiB | 0 bytes/s, done.
Total 18 (delta 5), reused 0 (delta 0)
To file:///c/code/blog/acme
* [new branch] acme -> upstream
Your work for Acme is done and you are lucky enough to land a new contract with Evil Corp. You negotiate with them to implement Feature 4 (something sufficiently generic that other clients might use it) and Feature Alpha just for them. Evil Corp benefits from your work for Acme and you begin by checking out the master branch and implementing Feature 4.
$ git checkout master
Switched to branch 'master'
$ emacs doc.txt
$ git diff
diff --git a/doc.txt b/doc.txt
index 5daa37c..2f6a3a6 100644
--- a/doc.txt
+++ b/doc.txt
@@ -7,5 +7,6 @@ It has features.
* Feature 1
* Faeture 2
* Feature 3
+* Feature 4
It is customizable.
$ git add doc.txt
$ git commit -m "Shared: Add feature 4"
[master c5ee2e8] Shared: Add feature 4
1 file changed, 1 insertion(+)
Then create a client-specific branch for Evil Corp and add their feature.
$ git checkout -b evil
Switched to a new branch 'evil'
$ emacs doc.txt
$ git diff
diff --git a/doc.txt b/doc.txt
index 2f6a3a6..53108fc 100644
--- a/doc.txt
+++ b/doc.txt
@@ -10,3 +10,7 @@ It has features.
* Feature 4
It is customizable.
+
+Evil Corp features include:
+
+* Feature Alpha
$ git add doc.txt
$ git commit -m "Evil: Add feature alpha"
[evil 65eab70] Evil: Add feature alpha
1 file changed, 4 insertions(+)
In testing the release for Evil Corp, you find and fix a problem with Feature 2.
$ git checkout master
Switched to branch 'master'
$ emacs doc.txt
$ git diff
diff --git a/doc.txt b/doc.txt
index 610f380..2f6a3a6 100644
--- a/doc.txt
+++ b/doc.txt
@@ -5,7 +5,7 @@ This document describes some soft
It has features.
* Feature 1
-* Faeture 2
+* Feature 2
* Feature 3
* Feature 4
$ git add doc.txt
$ git commit -m "Shared: Fix a bug in feature 2"
[master 4488af0] Shared: Fix a bug in feature 2
1 file changed, 1 insertion(+), 1 deletion(-)
And merge that fix into the Evil branch.
$ git checkout evil
Switched to branch 'evil'
$ git merge master
Auto-merging doc.txt
Merge made by the 'recursive' strategy.
doc.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
Finally, you deliver the code to Evil Corp.
$ cd ..
$ mkdir evil
$ cd evil/
$ git init
Initialized empty Git repository in C:/Code/blog/evil/.git/
$ cd ../shared/
$ git remote add Evil file:///c/code/blog/evil
$ git push Evil evil:upstream
Counting objects: 24, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (22/22), done.
Writing objects: 100% (24/24), 2.17 KiB | 0 bytes/s, done.
Total 24 (delta 7), reused 0 (delta 0)
To file:///c/code/blog/evil
* [new branch] evil -> upstream
At this point, Acme notices the bug in Feature 2 and asks you for a fix. Lucky you, you already fixed it. If Acme is willing to accept Feature 4, you can just merge your master to acme.
$ git checkout acme
Switched to branch 'acme'
$ git merge master
Auto-merging doc.txt
Merge made by the 'recursive' strategy.
doc.txt | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
If they are not, you can cherry-pick the fix for Feature 2 from master to acme. In either event, you then push your update to them.
$ git push Acme acme:upstream
Counting objects: 9, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 907 bytes | 0 bytes/s, done.
Total 9 (delta 3), reused 0 (delta 0)
To file:///c/code/blog/acme
20a8851..eb3f53a acme -> upstream
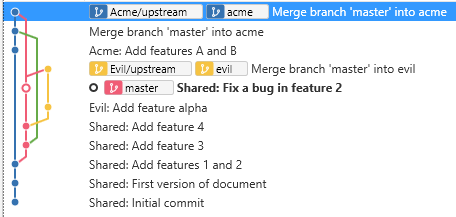
At this point, you can see your work for both clients.

Overview of all code
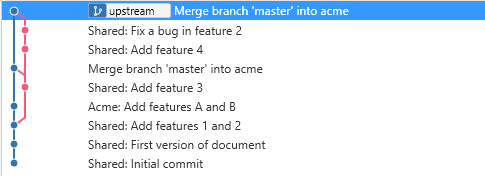
But your clients can only see the common code and their client-specific code.

Acme’s view of their code

Evil Corp’s view of their code
Furthermore, your clients can update their code (or the common code) and share it with you on their upstream branch. You can fetch that branch and cherry-pick fixes from it to your master branch to share with other clients as appropriate.