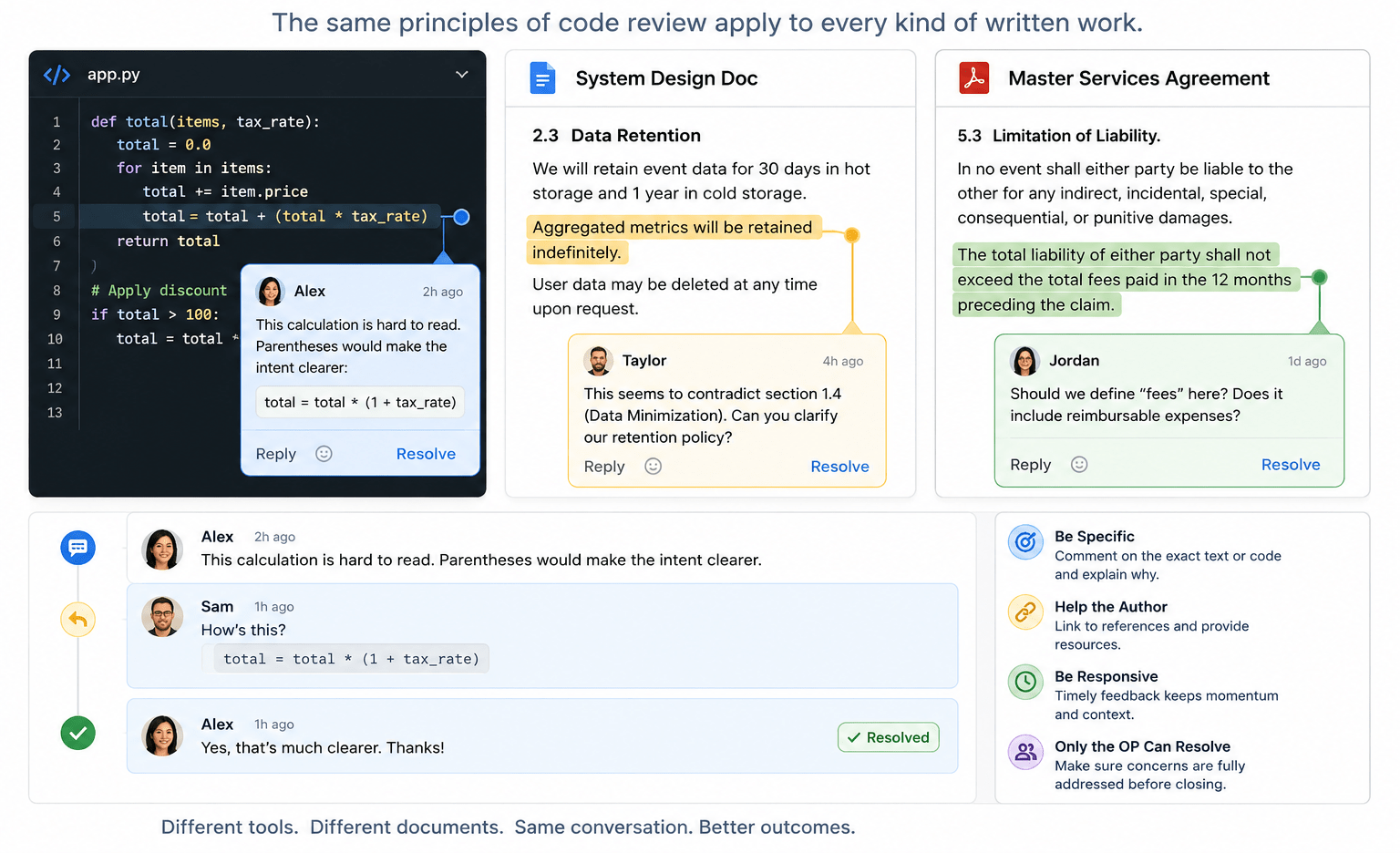
What is a DAG and Why Should You Care?
DAG stands for Directed, Acyclic Graph. It sounds a bit obscure but it has many practical applications, especially in software design. But what is it? The first two words are just modifiers so, what is a graph?
Fundamentally, a graph is a mathematical abstraction. I could tell you it is made up of nodes and edges but that’s still fairly abstract. You can visualize a graph as being islands (the nodes) connected by bridges (the edges), or cities and the roads connecting them. Indeed, one of the classic software problems, the traveling salesman, is about just such a scene. The salesperson wants to visit their customers on all of the islands without visiting any island (or using any bridge) twice. Is it possible? Can you write a program to do it? Or a program to show it’s not possible?
There are many variations on the problem. What if each bridge had a different toll and the goal is not to avoid repeats but to minimize total tolls paid?
Another interesting variation arises when the bridges or roads allow traffic to pass in only one direction. In the concrete, we recognize this as a one-way street. In the abstract, it is a directed edge: an edge that can be used to go from A to B but not back from B to A.
A poor traveler with a bad map or a bad sense of direction might set out on a trip across these one-way bridges and come to realize they have been driving in circles (A to B to C and somehow back to A). A good civil engineer might be able to set the direction of the bridges so that you couldn’t go in circles. The graph corresponding to these islands and bridges has no cycles, it’s acyclic.
So, a directed, acyclic graph is one where the edges have direction and you can’t return to your starting point following the direction of the edges.
But why should you care?
Graphs are abstract but describe various real-world problems very well. For example, consider the files and folders (or directories) on your computer. We’re used to seeing these presented as an outline where you can navigate down from the root of the disk to a folder in the root, to another folder inside that, and so on and so on. An outline or organization like this is a “tree,” a special type of directed graph where there is only one path from the root to the leaf. Picture a real tree and you see the same thing: for any leaf, there is only one path from root to trunk to limb to branch to twig to leaf.
For a more complex example, consider trying to classify animals that have frequent contact with people. We’ll exclude animals seen on safari or in zoos. We can start by dividing them into Farm Animals and Pets. Horse, pig, chicken: all farm animals. Goldfish, canaries, guinea pigs: all pets. What about dogs? Dogs are great pets but they also are used on farms to herd livestock. So is a dog a farm animal or a pet? It’s both. You can’t really use a tree to draw these categories but you can use a DAG! There are two paths from the root to dog: Frequent Contact → Farm Animals → Dog, and Frequent Contact → Pets → Dog. (We could divide farm animals into food animals and work animals, or pets into cuddly and not cuddly but dogs still fit two categories.) A dog is not a goldfish or a pig but because going from one category to a subcategory is directional, we’ll never be confused about that.
A Simple DAG Database
Codd and others did a lot of work creating relational databases. Open source tools like MySQL and products like SQL Server have decades or maybe centuries of labor in them to implement those theories. An edge is a relationship between two nodes so why wouldn’t you use a relational database to store it? Why reinvent the wheel?
You might say because node and edge aren’t SQL types but neither are bank account and product, but banking and e-commerce systems certainly use relational databases.
How do we represent a node in SQL? A table, naturally. What columns does the table have? Names are convenient for people to refer to things but numeric IDs are somewhat better for computers. So, let’s say a node has an ID, a name, and (why not?) a description.
CREATE TABLE [dag].[DagNode](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](50) NOT NULL,
[Description] [nvarchar](250) NULL)
An edge connects two nodes. The ID we gave nodes gives us an easy way to represent the nodes. The natural way to present this is a two-column table where each row is two IDs: one for the parent (the source of the edge) and one for the child (the destination of the edge).
CREATE TABLE [dag].[DagEdge](
[ParentID] [int] NOT NULL,
[ChildID] [int] NOT NULL)
Leaves and Referential Integrity
The table creation above omits the referential integrity constraints in my live database. The DagEdge table in my database has foreign key constraints that make sure both IDs refer to an actual node.
But what about leaves? In graph theory, a leaf is a node with only one edge. But that has some limitations in a database. First, the items we’re organizing in a DAG likely have different attributes than the name and description on a node. So, we create a new table for our leaves.
CREATE TABLE [dag].[DagLeaf](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](50) NOT NULL)
But then, we can’t use DagEdge to connect a node to a leaf because of the foreign key on ChildID. So, we create a new table to hold the node/leaf relationships.
CREATE TABLE [dag].[DagNodeLeaf](
[NodeID] [int] NOT NULL,
[LeafID] [int] NOT NULL)
And then add foreign keys to those referring to DagNode and DagLeaf, respectively.
While the DagNode and DagEdge tables are generic, we need a data table and a relation table for every type of data we’re going to organize into DAGs.
Examples
Code supporting this post is available on GitHub. That includes a script to create the tables mentioned above (complete with indices and constraints), a script to populate with some sample data, and a script full of sample queries to show how the data and functions behave. My examples are for SQL Server. Other databases of interest are MySQL and Postgresql. I’m happy to consider pull requests for those or others you may choose to implement.
Thanks
Thanks to CyberReef for allowing me to share this code. Something like it is used in the MobileWall product and related services. Hopefully, I didn’t add too many bugs as I tried to abstract the concepts.
Thanks, also, to my colleagues Carmen, Jessica, and Siva who reviewed the original code and provided valuable feedback.