I recently had the pleasure and privilege of presenting for the third time at Sharatoga Tech Talks. I previously talked about using Jira REST APIs to report on issue data outside of Jira. This time I expanded on that to present a technique for projecting a team’s workload for several software releases to help manage work and ensure on-time delivery.
When I read Edward Tufte’s excellent The Visual Display of Quantitative Information, I was impressed with his discussion of information density in great graphics. One of the many notable examples is Minard’s illustration of Napoleon’s failed Russian campaign, which, Tufte says, “may well be the best statistical graphic ever drawn.”

Among other information crammed into this graphic, the beige line shows advance and black lines show retreat with the width of the lines showing the declining strength of the force as it moved. The scale at the bottom shows the temperatures endured during the retreat.
There is a great deal of accessible and useful information in the book but my favorite of Tufte’s observations is, “Pie charts should never be used.” And yet, both Trac and Jira used pie charts for workload.

This chart leaves many unanswered questions. Are we on track to finish on time? Are any team members overworked? Can other team members take on some of their burden? Surely we can do better.

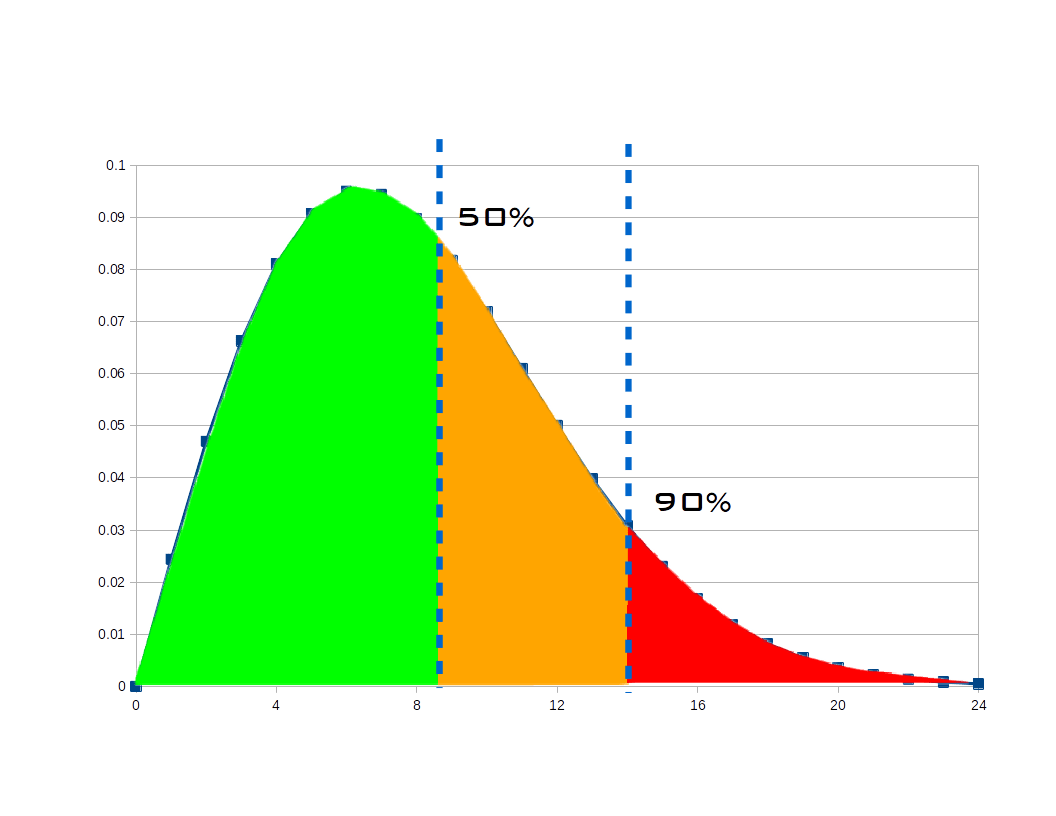
With a bar chart, we much more readily see the relative workloads of team members. Using a time scale for the Y axis allows us to see how much work each team member has. And knowing when the work is due and how fast work is usually completed, we can add a capacity threshold line showing how each member’s work compares to the amount likely to get done.
Long before reading Tufte, I had realized the low information density of pie charts and my development in Trac had included reworking Trac’s workload from pie charts to bar charts. Tufte inspired me to recreate and extend that work based on Jira data.
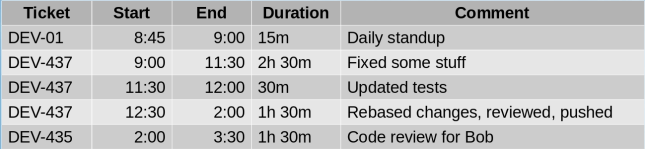
Release Workload

My Jira workload chart presents a lot of information in a small space.
- the release this work is for
- the date the work is due
- the amount of work we can expect to complete by that date
- the total number of hours due by that date
- the total number of issues due by that date
- the developers working on the release
- the number of hours assigned to each developer
- the number of issues assigned to each developer
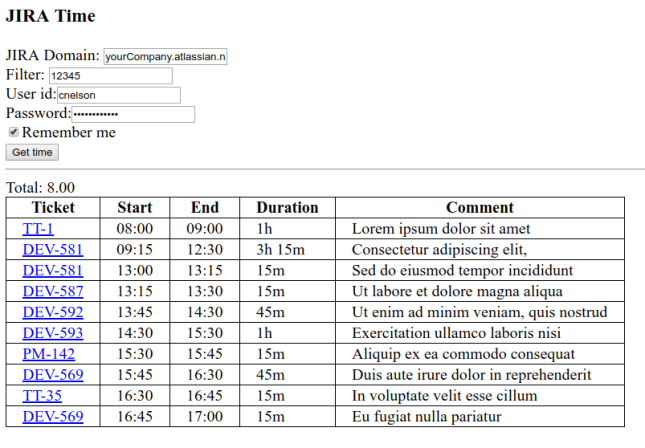
Navigation
One of the things I love about Trac is that it is rich in crosslinks supporting drilling down to alternate views or more data. (Jira has links, too, but they don’t always go where I want or expect.) My workload chart follows this philosophy and clicking on different parts of the chart results in Jira issue search results showing the related issues:
- Clicking on the release shows all the work in that release. (Because multiple releases may be due on the same date, each release leads to a different search result.)
- Clicking on the date shows all the work due then. (If there are multiple releases on a date, clicking on the date shows all the work for all of the releases.)
- Clicking on the bar or name for a developer shows all the work assigned to that developer.
Alternate Views
Looking at workload across the development team is useful but once we have the data, we can analyze it in other ways, too. A Kanban board shows how work progresses through stages and gives you an idea how close to done you are. By showing work by issue status we get the same result in a bar chart.

My workload chart can also show work by issue type (bug, enhancement, etc.) or project, measure work in hours or story points, and provide a default estimate for unestimated issues.

Projection
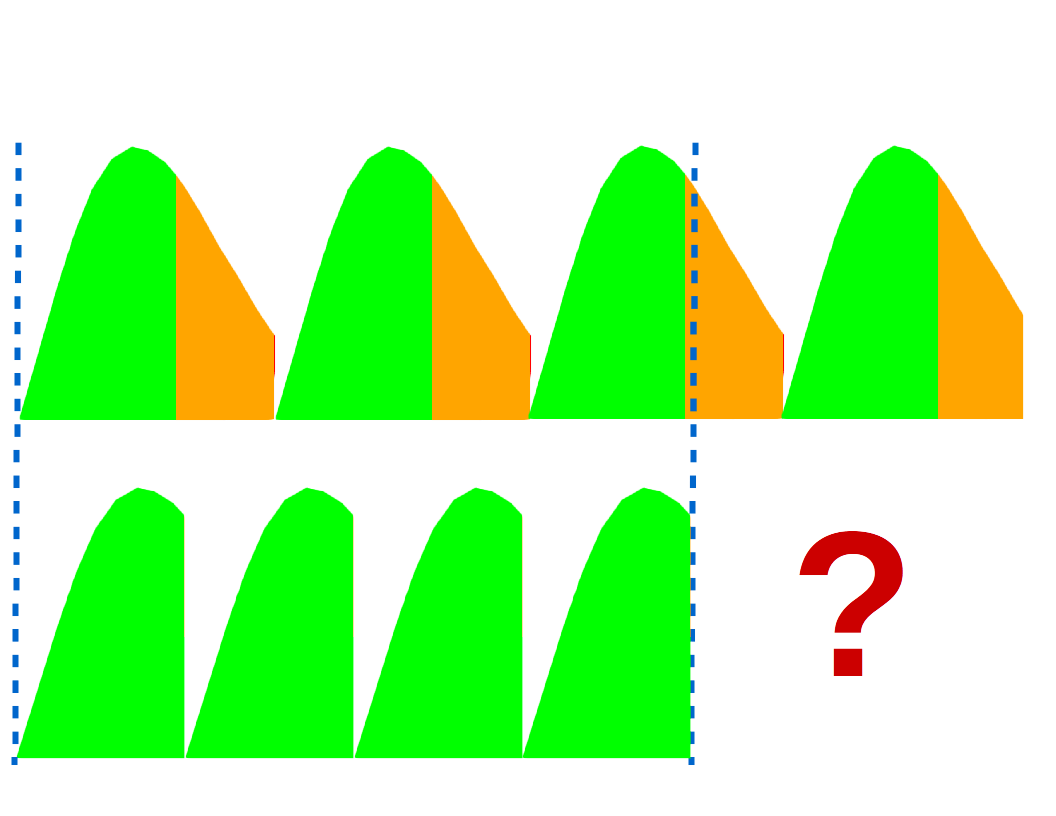
I find great value in an isolated workload chart for a single release or date but adding a time dimension and projecting workloads for future releases takes it to another level.
Let’s look at the workload for v1.0 again. You may think Marvin is a slacker. He doesn’t have much to do for v1.0 and you’d be tempted to see if he could help Daffy out.
But charting the next two releases tells a different story. Each chart includes all the work from the previous releases plus new work for the specific release. Marvin is still fairly lightly loaded for v1.0.1 and v1.1 but looking further we see that, starting now, Marvin is actually at risk for delivering all his work for release v1.2.


Now we know that to deliver v1.2 on time, we likely need to redistribute some of Marvin’s work. We can click through to see what makes up that workload and make informed decisions about redistributing it in a way that allows us to have confidence about the delivery of all of our planned releases.