A long time ago I implemented a program that learned to play Tic Tac Toe. I was a new programmer and not particularly skilled but I’d read an article about how someone had taught a matchbox to play and I thought I was at least that good. The article I’d read was in Scientific American but you can read about MENACE today on Wikipedia. The original work was “AI” in 1961! My program started out only “knowing” the allowable moves and as we played it “learned” strategy. After a dozen or so games, I couldn’t beat it. Even though I wrote it, I marveled at this program’s behavior.
Arthur C. Clarke famously said, “Any sufficiently advanced technology is indistinguishable from magic.” There are 512 possible final boards of Tic Tac Toe and more than 250,000 games (paths from an empty board to one of those 512 finishes). This is on the border of the ability of a human to inspect and understand. The fact that I didn’t really know how my program kept me from winning Tic Tac Toe didn’t make it magic, it was just sufficiently complex that I couldn’t intuit its inner workings. (I was a novice programmer then but decades years later I still find wonder in this program.)
Like those matchboxes and my novice program, a lot of things these days are called “artificial intelligence” but how intelligent are they? I’d argue, “not very.”
Neural Networks
Many AI systems — including my program — are trained to achieve their goal. The system starts with some constraints and rules then by exposing it to data (games of Tic Tac Toe, for instance), you train it or it learns how to behave in a way that seems intelligent.
One type of system that can be trained to seem intelligent is a neural network, based at least loosely on a limited understanding of how the brain works. With a neural network (NN), you repeatedly apply inputs and desired or expected output, and the network magically sets itself up to produce that output when the same or similar inputs are presented. (Please take a hint from the use of “magically” to realize that I’m being vague and general. I’m sure I’ve got details wrong.)
A common demonstration of neural networks is classification of data like images or audio clips. After training, you might use a NN to try to tell if a sound came from a flute or a saxophone, or what kind of animal was in a picture. Say you had several (or several hundred) images of cats and dogs. You might try to train a neural network to discriminate between them.
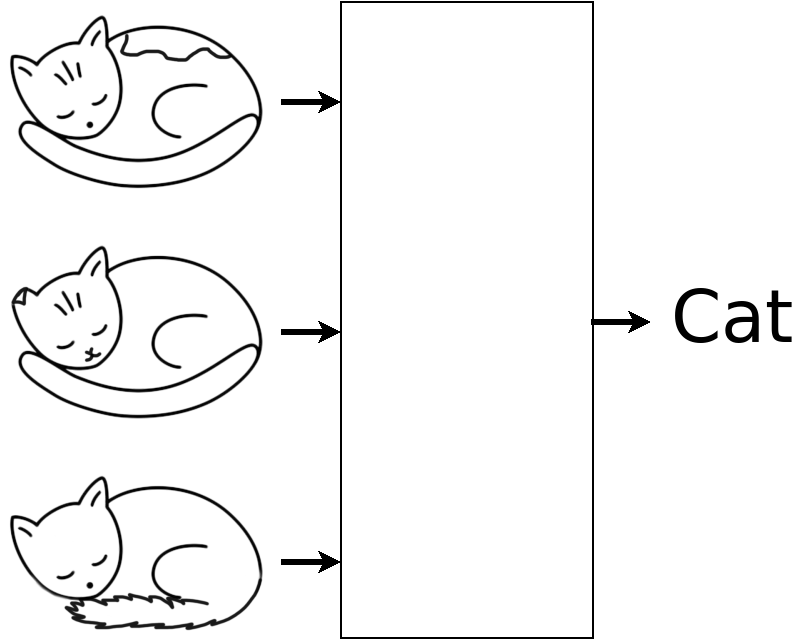
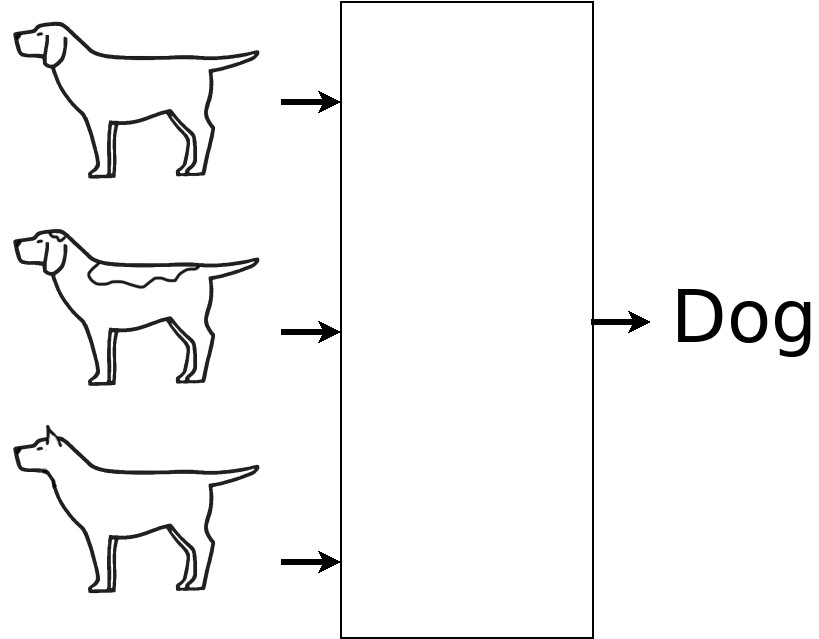
The test is trying the NN on a novel input.
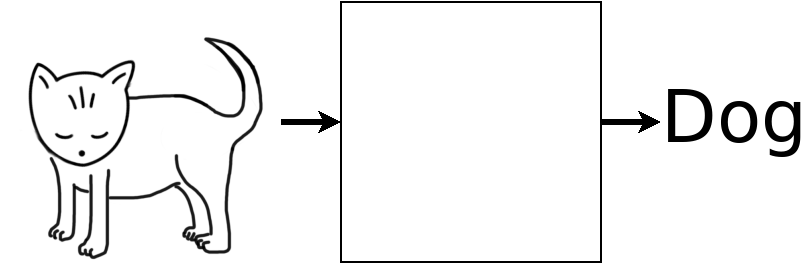
What Went Wrong?
Somehow, the NN might have noticed that the cats all have a horizontal stroke at the bottom center but the dogs are all hollow. That fits the training data and leads to the same wrong conclusion with the test data.
Whatever the method, the NN focused on the wrong feature of the input and drew the wrong conclusion. When shown an image of a standing animal, it labeled it a dog. This is a classic example of GIGO: garbage in, garbage out.
Considering this small training set, we could try to fix the problem by adding standing cats and sitting dogs to the training images. Then the NN might focus on pointy tails or some other irrelevant feature and still reach the wrong conclusion. (Challenge: can you explain the difference between a cat and a dog well enough for another person following your directions to properly conclude the last image is a cat?)
Humans are great at pattern recognition and extrapolation, at least to the limits of our capacity. We can look at the data we trained the NN with and see things that might be wrong. But if you trained the NN on thousands of drawings (or thousands of photos!), it would be nearly impossible for a human to review the training data, determine the problem, and fix it. The larger the data set, the harder it is to tell what is wrong or to correct the problem.
Generative “AI”
If you play Scrabble or Wordle, you are likely familiar with the fact that “e” is the most common letter in English text. Different analyses show “t” or “a” second. As you might expect, “q” and “z” are fairly uncommon. What if you looked for the frequency of two-letter combinations? You might think “th” would be fairly common (indeed, it’s the most common) and something like “qz” fairly uncommon or absent. Things get interesting with three-character combinations; It turns out they embody a lot of the word-forming rules of the language. If you “randomly” generate text that adheres roughly to the same frequency of trigrams as the original language, you get something that is readable nonsense. Readable, because all the letter combinations look familiar to us and we can sound them out. Nonsense because there are very few actual words in the text.
What if, instead of the frequency of one letter following another, we considered the frequency of one word following another. If we had a large volume of text to train the system with, we could generate novel text from that training set.
If you used all of Shakespeare’s plays as a training set and asked the system to generate some text, it could. The output might be fairly readable (though it likely wouldn’t have much of a plot). But it would be in Shakespeare’s English, not modern, with nary an acronym or neologism in sight. And it would be more like a play than the sonnets Shakespeare is also famous for.
While Shakespeare was prolific, his collected work is still a small part of a small library. And it is microscopic compared to all the text on the Internet: digitized books but also software user manuals, scientific papers in online journals, social media posts, and on and on. That huge volume of text is what is used to train large language models (LLMs). Once the LLM is trained with a large fraction of the Internet, you can ask it to generate novel content. This content will sometimes be gibberish but a really good system will produce text that seems quite coherent.
If a LLM’s training material includes racist rants on social media, there’s a chance it will generate text that reflects that bigotry. Does the LLM have a conscious bias against certain people? No, it’s not even conscious. But it can look that way. And it’s not a good look. Remember GIGO. The system reflects the strengths and weaknesses and biases of the input. Do cats always lie down? Are plays always in Shakespeare’s voice?
A lot has happened since 1961 and many years since have been labeled the “year of AI.” Recent developments have lead to AI techniques yielding more useful applications. Maybe that year has finally come. With AI as with many things, we should be mindful of creators’ intent and the systems’ affects but let’s not cloak such applications in mystery.
One response to “Not So Intelligent”